Overview
| Philosophy | 1) Benchmark language implementations, not individual programs (simple tasks with few pitfalls). 2) Benchmark one language a time, not a mixture of languages (no non-standard libraries in other languages; no language extension). |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5440 @ 2.83GHz |
| Memory | 16GB |
| OS | Debian GNU/Linux 5.0 |
| Source code | https://github.com/attractivechaos/plb (MIT licensed) |
| Note on update | The benchmark was originally conducted in June, 2011. The results for a few implementations have been updated since then, but others have not. The original results can be found at here. The picture below is for the old results. |
Benchmarks
| sudoku:t | CPU time in seconds for solving 20x50 Sudokus (20 extremely hard Sudokus repeated 50 times) using an algorithm adapted from suexco. This algorithm is not the fastest, but it is very easy to reimplement. Note that "sudoku" and "matmul" evaluate the performance of the language itself. "Patmch" and "dict" below effectively evaluate the performance of libraries. |
|---|---|
| matmul:t | CPU time in seconds for multiplying two 1000x1000 matrics using the standard cubic-time algorithm. This benchmark evaluates the performance of nested loops with a simple inner loop, which is frequent in scientific computing. |
| matmul:m | Memory in megabytes for multiplying two 1000x1000 matrics using the standard cubic-time algorithm. |
| patmch:1t | CPU seconds for finding lines matching regexp "([a-zA-Z][a-zA-Z0-9]*)://([^ /]+)(/?[^ ]*)" in this file. This benchmark evaluates the performance of regex matching common in the context of biological sequence analyses. The uncompressed text file is copied to /dev/shm to avoid I/O overhead. For C, reading the input file line by line with fgets() takes 0.1 CPU second. |
| patmch:2t | CPU seconds for finding lines matching "([a-zA-Z][a-zA-Z0-9]*)://([^ /]+)(/?[^ ]*)|([^ @]+)@([^ @]+)" in this file. This benchmark evaluates the performance given the "|" regex operator which is known to hurt back-tracking based regex matching algorithms. |
| dict:t | CPU seconds for counting the occurrence of each distinct string among 5 million strings. The average occurrence is 4. This benchmark evaluates the efficiency of associative arrays. The strings are generated by this program. For C, reading the input file line by line takes 0.3 CPU second. |
| dict:m | Memory in megabytes for counting the occurrence of each distinct string among 5 million strings. |
Results
| Implementation | Lang | sudoku:t | matmul:t | matmul:m | patmch:1t | patmch:2t | dict:t | dict:m |
|---|---|---|---|---|---|---|---|---|
| ICC-12.0.3 | C | 1.0 | 1.8 | 31.8 | 1.6 | 4.1 | 3.0 | 52.6 |
| GCC-4.3.2 | C | 1.0 | 2.3 | 31.7 | 1.7 | 4.5 | 3.0 | 52.6 |
| Clang@LLVM-2.9 | C | 1.0 | 2.3 | 31.7 | 1.8 | 4.1 | 3.0 | 52.6 |
| Java@JRE-1.6.0_25 | Java | 1.7 | 2.6 | 67.1 | 6.8 | 13.4 | 6.7 | 314.8 |
| C#@Mono-2.10.1 | C# | 3.8 | 8.9 | 40.6 | 15.7 | 45.1 | 5.2 | 113.9 |
| 6g-20110424 | Go | 2.3 | 3.1 | 38.2 | 21.4 | 56.1 | 4.7 | 154.5 |
| GDC-0.24 | D | 1.1 | 3.3 | 33.9 | 999.9 | 999.9 | 3.1 | 92.4 |
| LDC-20110428@LLVM-2.9 | D | 1.1 | 2.4 | 31.4 | 999.9 | 999.9 | 999.9 | 999.9 |
| V8-r8384 | Javascript | 3.7 | 2.6 | 141.6 | 1.7 | 3.0 | 7.3 | 97.3 |
| JaegarMonkey-a95d42642281 | Javascript | 18.1 | 16.4 | 35.8 | 1.9 | 2.8 | 9.3 | 274.6 |
| LuaJIT-2.0.1 (JIT-on) | Lua | 3.7 | 2.5 | 33.2 | 6.2 | 999.9 | 4.5 | 123.8 |
| LuaJIT-2.0.1 (JIT-off) | Lua | 15.9 | 20.8 | 33.0 | 6.2 | 999.9 | 4.6 | 123.6 |
| llvm-lua-1.3.1@LLVM-2.8 | Lua | 26.9 | 31.1 | 73.4 | 6.8 | 999.9 | 5.2 | 164.0 |
| Lua-5.1.4 | Lua | 50.5 | 68.3 | 65.4 | 6.2 | 999.9 | 5.7 | 197.6 |
| Perl-5.12.2 | Perl | 121.2 | 230.3 | 225.6 | 0.5 | 12.6 | 6.3 | 219.9 |
| PyPy-1.4.1 | Python | 19.5 | 8.5 | 84.1 | 4.0 | 7.3 | 12.3 | 236.0 |
| CPython-3.2 | Python | 119.9 | 121.9 | 93.2 | 5.7 | 13.8 | 5.1 | 154.1 |
| CPython-2.7.1 | Python | 113.9 | 153.9 | 91.3 | 5.5 | 12.6 | 4.1 | 112.6 |
| IronPython-2.7@Mono-2.10.1 | Python | 100.9 | 202.7 | 190.2 | 21.9 | 49.9 | 13.6 | 188.6 |
| Jython-2.5.2@JRE-1.6.0_25 | Python | 136.3 | 731.4 | 355.6 | 43.2 | 125.0 | 12.3 | 457.0 |
| Shedskin-0.9@GCC-4.3.2 | Python | 4.4 | 3.7 | 50.4 | 1.1 | 11.0 | 6.9 | 331.1 |
| R-2.13.0 | R | 999.9 | 1736.3 | 57.2 | 34.6 | 47.7 | 999.9 | 999.9 |
| JRuby-1.6.1@JRE-1.6.0_25 | Ruby | 71.1 | 238.2 | 342.5 | 5.5 | 23.1 | 18.1 | 436.9 |
| IronRuby-1.1.1@Mono-2.10.1 | Ruby | 249.3 | 510.0 | 176.0 | 25.5 | 54.5 | 39.6 | 367.2 |
| Ruby-1.9.2p180 | Ruby | 98.0 | 628.4 | 196.6 | 15.4 | 30.3 | 8.6 | 156.8 |
| Rubinius-1.2.3 | Ruby | 135.5 | 298.1 | 162.5 | 20.1 | 33.8 | 97.0 | 273.4 |
Notes
| General |
1) C programs are compiled with "gcc/clang -O3 -fomit-frame-pointer" or "icc -O3 -fomit-frame-pointer -xSSE4.1" 2) D programs are compiled with "ldc -O3 -release" or "gdc -O3 -frelease -inline". 3) Mono-sgen is used for implementations requiring the .NET framework. Mono-sgen is usually faster but costs more memory than mono. 4) `999.9' in the table indicates that the language does not support the feature or no implementations are available. |
|---|---|
| sudoku:t |
1) For these Sudokus, JSolve can find the solutions in 0.23 CPU seconds. 2) My Javascript implementation is also available here as a web page. |
| matmul:t matmul:m |
1) LDC, PyPy, CPython2/3, JS, LuaJIT and IronPython use "v2" and the rest use "matmul_v1.*" in the source code directory. 2) The built-in Matrix class in Ruby does not transpose the second matrix before multiplication. Using the built-in class is twice as slow. 3) Using the built-in matrix multiplication operator, R takes 2.7 sec in 57.0 MB memory, a huge difference. |
| patmch:1t |
1) The file used in the benchmark contains non-ASCII characters, which
are removed by this program. 2) C uses "patmch_v2.*" and the rest use "patmch_v1.*" in the repository. 3) The regexp9 library from the Plan 9 project is used for the C implementation. Better libraries exist in C++. 4) I cannot get the D implementation working. Rhino works for the Javascript program, but run extremely slow. 5) Lua does not come with a real regex engine, so its string pattern matching functions were used instead, which were not intended for speed. |
| patmch:2t | 1) Lua built-in string matching, which is different regex matching, does not support the "|" regex operator. |
| dict:t dict:m |
1) All language implementations use "dict_v1.*" in the repository. 2) My khash library is used for the C implementation. The C++ implementation takes 3.4 sec using 71.1MB memory. 3) The C implementation manipulates the memory, which may be unfair to other implementations. |
Appendix: the Bar Chart
In the following plots, a number in red indicates that the corresponding implementation requires explicit compilation; in blue shows that the implementation applies a Just-In-Time compilation (JIT); in black implies the implementation interprets the program but without JIT.

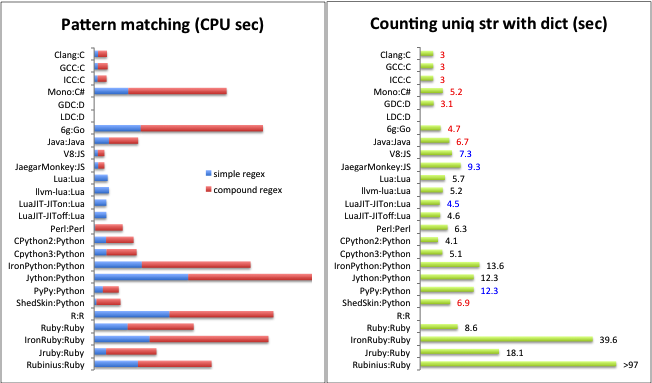
The bar chart is updated on June 21, 2011. It may not always be synchronized with the table.